Artificial intelligence
Why are Large Language Models getting special attention?
Fully grasping large language models means first understanding deep learning techniques.
Fully grasping large language models means first understanding deep learning techniques.
As a subset of machine learning, deep learning teaches computers to learn by example (as humans do).
Deep learning is a catalyst in many AI automation-based applications that perform analytical and physical tasks without human participation. Associated technologies can be found in our daily products and services (e.g., credit card fraud detection, voice-enabled TV remotes, and digital assistants).
Self-driving cars are also powered by deep learning techniques, helping vehicles halt at stop signs and tell the difference between lampposts and pedestrians.
LLMs are a type of deep learning linked to generative AI.
To the above point, LLMs are a type of generative AI designed to generate text-based content.
Historical context for Large Language Models
Spoken languages have been part of human existence for millennia.
Language gives us the words, grammar, and semantics to explain concepts and ideas–it’s at the centre of all human and tech-based communications.
AI language models perform similar functions, offering a basis for communication and innovation.
The roots of AI language models go back to the ELIZA language model that debuted at MIT in 1966.
LLMs are at the next stage of evolution, innovation, and digital transformation in the AI-drive language model concept.
Marco Hutter, LeMo
Since those days, many of the core principles of language models have stayed the same. All language models initially get trained on a data set. These models infer relationships using given techniques and generate fresh content based on the trained data.
Language models are commonly used in natural language processing (NLP) applications where a user inputs a query in natural language to generate a result.
LLMs are at the next stage of evolution, innovation, and digital transformation in the AI-drive language model concept.
LLMs: the fully evolved language model
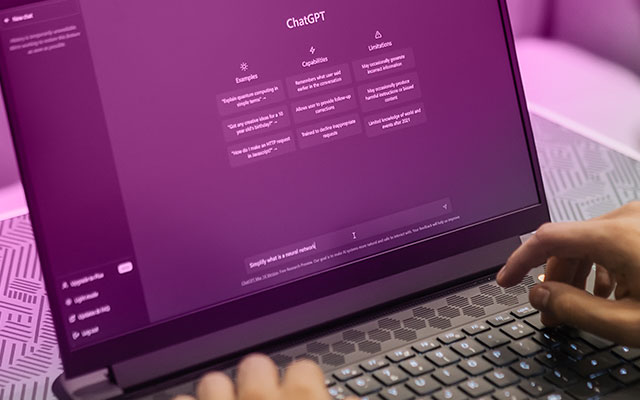
LLMs vastly expand upon the data used for interference and training compared to previous language model concept iterations. Thus, LLMs offer significantly enhanced capabilities in the AI model.
A universally accepted data set benchmark for training doesn’t yet exist for LLMs. Nonetheless, this AI-powered tech contains one billion-plus parameters (at a minimum).
In their more evolved form, LLMs burst onto the scene in 2017. They use transformer neural networks (aka transformers).
Bolstered by vast parameters and the transformer model, today’s LLMs can grasp concepts and rapidly generate correct responses. Thus, LLMs have contributed to AI technology’s ubiquitous nature and how it’s now applicable throughout increasingly more domains.
The nuts and bolts of LLMs
Foundationally, LLMs require training with large data volumes (often called a corpus). The available data will be petabytes in size.
Multiple steps are often required for the training, beginning with an approach referred to as unsupervised learning.
During the unsupervised learning phase, unstructured and unlabeled data train the model. Unlabeled data training leverages the vast increase in available data this method provides. The model starts deriving relationships between various concepts and words during this stage.
The next stage in many LLM training processes involves a form of self-supervised learning for fine-tuning. Some data has been labelled at this point, helping the model identify different concepts more accurately.
From there, deep learning is applied to LLM training. The LLM will simultaneously undergo the neural network process, enabling it to recognise connections and relations between concepts and words with a self-attention mechanism. This mechanism gives a score (or a weight) to the appropriate item (or a token) to decipher the relationship.
Once the LLM training is complete, the AI has a base it can rely on for practical applications. The AI model inference can generate a response by querying the LLM with a prompt. The response could be newly generated text, an answer, sentiment analysis, or summarised text.
The model starts deriving relationships between various concepts and words during this stage.
Marco Hutter, LeMo
What are the primary functions of LLMs?
LLMs are generally used for the following purposes:
- LLMs can be trained in multiple languages. They can translate from one language to another.
- Text generation on any topic the LLM has been taught is a frequent use case.
- A section of text can quickly be rewritten using an LLM.
- LLMs can summarise multiple pages or large blocks of text.
- The majority of LLMs can provide sentiment analysis, aiding users who seek a better understanding of content or specific responses.
- Users of LLMs can seamlessly categorise and classify content.
- Chatbots and conversational AI are the most popular use cases for LLMs. LLMs enable user-based conversations more naturally than previous AI iterations.
Large Language Models are worthy of their special attention
Spoken languages have been part of human existence for millennia.
Language gives us the words, grammar, and semantics to explain concepts and ideas–it’s at the centre of all human and tech-based communications.
AI language models perform similar functions, offering a basis for communication and innovation.
The roots of AI language models go back to the ELIZA language model that debuted at MIT in 1966.








Share this article





